

Hace dos años, el ex presidente Barack Obama anunció el Iniciativa de medicina de precisión en su discurso sobre el Estado de la Unión. La iniciativa aspiraba a una "nueva era de la medicina" donde los tratamientos de enfermedades podrían adaptarse específicamente al código genético de cada paciente. ![]()
Esto resonó profundamente en la medicina contra el cáncer. Los pacientes ya pueden controlar su cáncer con terapias dirigidas a los genes específicos que están alterados en su tumor particular. Por ejemplo, las mujeres con un tipo de cáncer de mama causado por la amplificación del gen HER2 a menudo se tratan con un tratamiento llamado herceptin. Debido a que estas terapias dirigidas son específicas de las células cancerosas, tienden a tener menos efectos secundarios que los tratamientos tradicionales contra el cáncer con quimioterapia o radiación.
Sin embargo, tales tratamientos no están disponibles para la mayoría de los pacientes con cáncer. En muchos cánceres, las alteraciones genéticas específicas que son responsables de un cáncer permanecen desconocidas. Para crear tratamientos individualizados para el cáncer, debemos saber más sobre las alteraciones genéticas funcionales.
Con los datos sobre la genética del cáncer creciendo rápidamente, las matemáticas y las estadísticas ahora pueden ayudar a desbloquear los patrones ocultos en estos datos para encontrar los genes que son responsables del cáncer de un individuo. Con este conocimiento, los médicos pueden seleccionar los tratamientos adecuados que bloquean la acción de estos genes para personalizar las terapias para pacientes individuales. Mi investigación tiene como objetivo mejorar la medicina de precisión en el cáncer, basándose en los mismos métodos que se han utilizado para encontrar patrones en las clasificaciones de películas de Netflix.
Examinando los datos
Hoy en día, existe un acceso público sin precedentes a los datos de genética del cáncer. Estos datos provienen de pacientes generosos que donan sus muestras de tumores para investigación. Los científicos luego aplican tecnologías de secuenciación para medir las mutaciones y la actividad en cada uno de los genes 20,000 en el genoma humano.

Todos estos datos son un resultado directo de la Proyecto del Genoma Humano en 2003. Ese proyecto determinó la secuencia de todos los genes que componen el ADN humano saludable. Desde la finalización de ese proyecto, el costo de la secuenciación del genoma humano ha más de la mitad cada año, superando el crecimiento del poder de cómputo descrito en La Ley de Moore. Esta reducción de costos permite a las investigaciones recopilar datos genéticos sin precedentes de pacientes con cáncer.
La mayoría de los estudios científicos sobre la genética del cáncer realizados en todo el mundo publican sus datos en una base de datos pública centralizada proporcionada por la Biblioteca Nacional de Medicina de los Institutos Nacionales de la Salud de EE. UU. (NIH). El NIH National Cancer Institute y el National Human Genome Research Institute también han publicado libremente datos genéticos de más de tumores 11,000 en tipos de cáncer 33 a través de un proyecto llamado El Atlas del Genoma del Cáncer.
Cada función biológica, desde la extracción de energía de los alimentos hasta la cicatrización de una herida, es el resultado de la actividad en diferentes combinaciones de genes. Los cánceres secuestrar los genes que permiten a las personas crecer hasta la edad adulta y que protegen el cuerpo del sistema inmune. Los investigadores doblan estos "Señas de identidad del cáncer". Esta llamada desregulación génica permite que un tumor crezca sin control y forme metástasis en órganos distantes del sitio original del tumor.
Los investigadores están utilizando activamente estos datos públicos para encontrar el conjunto de alteraciones genéticas responsables de cada tipo de tumor. Pero este problema no es tan simple como identificar un solo gen desregulado en cada tumor. Cientos, si no miles, de los genes 20,000 en el genoma humano están desregulados en el cáncer. El grupo de genes desregulados varía en el tumor de cada paciente, con conjuntos más pequeños de genes comúnmente reutilizados que permiten el sello de cada cáncer.
La medicina de precisión se basa en encontrar los grupos más pequeños de genes desregulados que son responsables de la función biológica en el tumor de cada paciente. Pero, los genes pueden tener múltiples funciones biológicas en diferentes contextos. Por lo tanto, los investigadores deben descubrir un conjunto de genes "superpuestos" que tienen funciones comunes en un conjunto de pacientes con cáncer.
Vincular el estado del gen a la función requiere matemáticas complejas y un poder de cómputo inmenso. Este conocimiento es esencial para predecir el resultado de las terapias que bloquearían la función de estos genes. Entonces, ¿cómo podemos descubrir esas características superpuestas para predecir los resultados individuales para los pacientes?
Lo que Netflix puede enseñarnos
Afortunadamente para nosotros, este problema ya se ha resuelto en informática. La respuesta es una clase de técnicas llamada "factorización matricial", y es probable que ya haya interactuado con estas técnicas en su vida cotidiana.
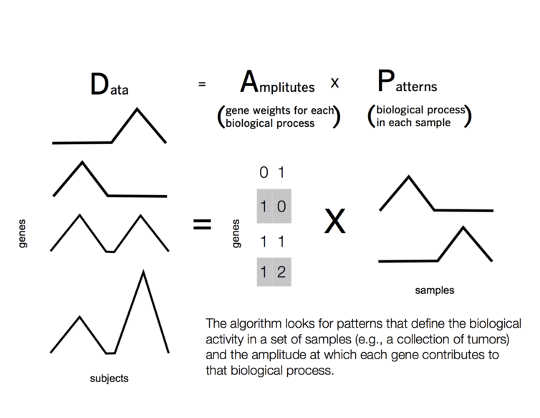
En 2009, Netflix tuvo un desafío para personalizar clasificaciones de películas para cada usuario de Netflix. En Netflix, cada usuario tiene un conjunto distinto de clasificaciones de diferentes películas. Mientras que dos usuarios pueden tener gustos similares en las películas, pueden variar enormemente en géneros específicos. Por lo tanto, no puede confiar en comparar calificaciones de usuarios similares.
En cambio, un algoritmo de factorización matricial encuentra películas con clasificaciones similares entre un grupo más pequeño de usuarios. El grupo de usuarios variará para cada película. La computadora asocia a cada usuario con un grupo de películas en diferente medida, según sus gustos individuales. Las relaciones entre los usuarios se conocen como "patrones". Estos patrones se aprenden a partir de los datos, y pueden encontrar clasificaciones comunes no previstas solo por el género de la película; por ejemplo, los usuarios pueden compartir una preferencia por un director o actor en particular.
 Genevieve Stein-O'Brien, CC BY
Genevieve Stein-O'Brien, CC BY
El mismo proceso puede funcionar en el cáncer. En este caso, las mediciones de la desregulación genética son análogas a las clasificaciones de películas, los géneros cinematográficos a la función biológica y los usuarios a los tumores de los pacientes. La computadora busca en los tumores del paciente para encontrar patrones en la desregulación genética que causa la función biológica maligna en cada tumor.
De las películas a los tumores
La analogía entre las calificaciones de las películas y la genética del cáncer se rompe en los detalles. A menos que sean menores, los usuarios de Netflix no tienen restricciones en las películas que miran. Pero, en cambio, nuestros cuerpos prefieren minimizar el número de genes utilizados para cualquier función. También hay redundancias sustanciales entre los genes. Para proteger una célula, un gen puede sustituir fácilmente a otro para cumplir una función común. Las funciones genéticas en el cáncer son aún más complejas. Los tumores también son muy complejos y evolucionan rápidamente, dependiendo de las interacciones aleatorias entre las células cancerosas y el órgano sano adyacente.
Para dar cuenta de estas complejidades, hemos desarrollado un enfoque de factorización de matriz llamado Actividad coordinada de genes en conjuntos de patrones - o CoGAPS para abreviar. Nuestro algoritmo explica el minimalismo de la biología al incorporar la menor cantidad posible de genes en los patrones para cada tumor.
Los diferentes genes también pueden sustituirse entre sí, cada uno de los cuales cumple una función similar en un contexto diferente. Para dar cuenta de esto, CoGAPS estima simultáneamente una estadística para los llamados "patrones" de la función del gen. Esto nos permite calcular la probabilidad de que cada gen se use en cada función biológica en un tumor.
Por ejemplo, muchos pacientes toman un medicamento dirigido llamado cetuximab para prolongar la supervivencia en cánceres colorrectales, pancreáticos, pulmonares y orales. Nuestro trabajo reciente encontró que estos patrones pueden distinguir la función del gen en las células cancerosas que responden al agente terapéutico dirigido cetuximab de aquellos que no lo hacen.
El futuro
Desafortunadamente, las terapias contra el cáncer que se dirigen a los genes generalmente no pueden curar la enfermedad de un paciente. Sólo pueden retrasar la progresión durante unos años. La mayoría de los pacientes luego recaen, con tumores que ya no responden al tratamiento.
Nuestro propio trabajo reciente encontró que los patrones que distinguen la función del gen en las células que responden a cetuximab incluyen los mismos genes que dan lugar a la resistencia. Las inmunoterapias emergentes son prometedoras y parecen curar algunos cánceres. Sin embargo, con demasiada frecuencia, los pacientes con estos tratamientos también recaen. Los nuevos datos que rastrean la genética del cáncer después del tratamiento son esenciales para determinar por qué los pacientes ya no responden.
Junto con estos datos, la biología del cáncer también requiere una nueva generación de científicos que puedan relacionar las matemáticas y las estadísticas para determinar los cambios genéticos que se producen con el tiempo en la resistencia a los medicamentos. En otros campos de las matemáticas, los programas de computadora pueden pronosticar resultados a largo plazo. Estos modelos se utilizan comúnmente en predicción del clima y estrategias de inversión.
En estos campos y mi propia investigación previa, hemos encontrado que las actualizaciones de los modelos de grandes conjuntos de datos, como los datos satelitales en el caso del clima, mejoran las predicciones a largo plazo. Todos hemos visto el efecto de estas actualizaciones, con las predicciones meteorológicas mejorando cuanto más nos acercamos a una tormenta.
Así como las herramientas de la informática utilizadas se pueden adaptar a las recomendaciones de la película y al cáncer, la futura generación de científicos computacionales adoptará herramientas de predicción de una serie de campos para la medicina de precisión. En última instancia, con estas herramientas computacionales, esperamos predecir la respuesta de los tumores a la terapia tan comúnmente como predecimos el clima, y tal vez de manera más confiable.
Sobre el Autor
Elana Fertig, Profesora Asistente de Bioestadística y Bioinformática de Oncología, La Universidad Johns Hopkins
Este artículo se publicó originalmente el La conversación. Leer el articulo original.
Libros relacionados
at InnerSelf Market y Amazon



















